
公司的项目数据量有限,获取行业线上线下消费数据也困难,没有足够的数据量,如何应用大数据?如何在公司现有情况下接触实际的高并发大数据项目?
就是想实操一下高并发的架构设计或者参与互联网级别项目的开发,但又不想舍弃现在的工作?
中小企业如何想办法破局
大数据本身就特别容易形成技术垄断,让长尾的中小企业无法形成自己可以拥有的大数据技术方法和经验,导致很难改变小企业的命运,而且也容易导致优质工程师的流失。如何想办法突破这个局面呢?
中小企业往往都是长尾的,小数据形态,基本上自身无法产生较大规模数据,更不具备建立数据共享平台的实力,而且与其他企业也存在着天然的信任隔阂,就很难做到企业数据之间的共享。这些本质的底层逻辑所产生的问题是中小企业很难通过联合产生足够规模的数据,所以很难应用大数据技术和大数据平台化所带来的优势。
但是中小企业若有机会,就一定要涉足大数据,因为智能互联网时代已经到来,要为将来的发展做铺垫,避免被轻易地淘汰掉,这个时代的企业强者愈强,弱者愈弱。
那有没有好的办法呢?中小企业可行的策略就是"吃大户",找大户合作,替大户服务,然后拿着大户的平台数据,锻炼着自己的大数据能力。这就必须要有过硬的业务与技术合作,开放的心态与持久的耐心!
举个例子,以前认识一个小微软件公司的架构师,公司通过商务运作,接手了一个省级的政府大数据项目,按照正常逻辑是没有能力承接啊!但是项目的关键要素是必须懂得核心业务数据如何去做数据清洗,我的朋友公司正好在这方面是业务专家,这才让企业全力以赴接手了这个项目,关键是请来了大数据方面的咨询师配合我的朋友架构师,就一起做成了该项目的技术架构及数据开发实施,经过两年左右的时间,迅速使企业具备了大数据项目的承接能力,从此到处标榜大数据技术企业了,我朋友也成为口碑比较厉害的大数据技术架构师了。
当然很多中小企业不是软件公司,但也可以建立大数据应用部门,招揽一些优秀的人才,或者与其他专业创业型大数据技术团队,形成战略同盟,紧扣自身行业所专长的数据业务,制定符合自身企业特色的发展战略。然后去找政府、电信、银行、能源、制造等具有产生大数据能力的大户,提供在大数据方面的服务解决方案,盘活大户的数据死海成为数据资产,通过服务的形式,使自己成为大数据战略的一个服务环节提供商,那么就充分具有了大规模数据的使用权,不仅能帮助大户提供采集,分析,运营数据的服务能力,也能快速打造自身企业在大数据时代的实力与铭牌。
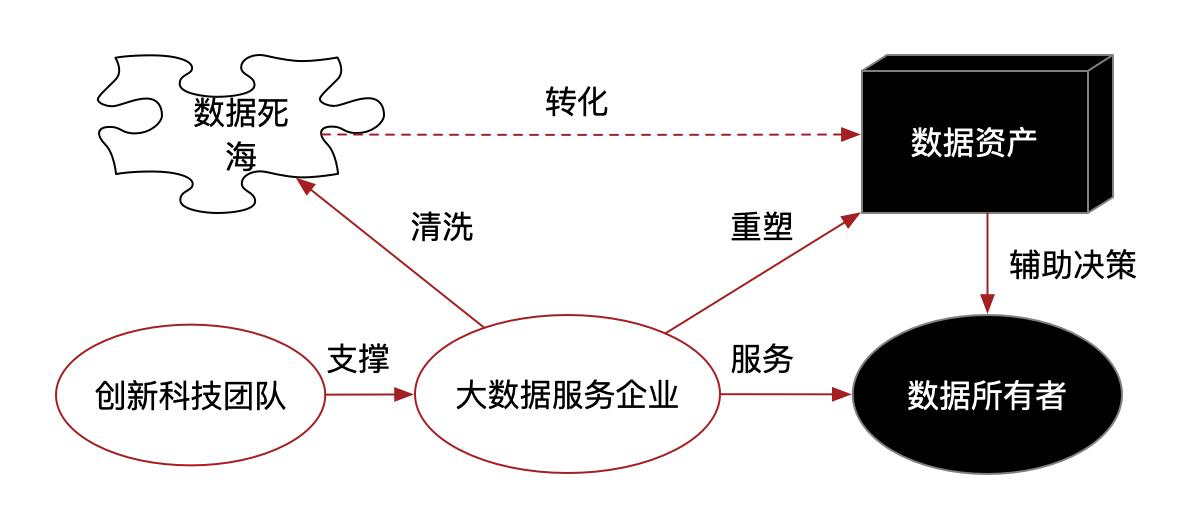
例如:你是做医疗设备的小厂商,虽然在垂直领域你很厉害,但是放眼发展,商业局限性就很大,若将自身铭牌改成医疗大数据与AI设备服务商,通过医疗设备作为数据采集的入口,进一步为政府提供医疗大数据清洗服务,并抓住一个或几个关键医疗分析的亮点数据分析需求,做成AI分析平台,并加入大数据采购名录,那么这家小企业的前景肯定就有很大改观了。
再例如:你是交通视频系统集成商,还把自己定位成系统设备集成商的话,那么你们始终摆脱不了竞争激烈,低利润的红海,若能与AI创新科技公司合作,那么借助你们对行业各种业务资源的灵活把握与市场转化能力,并将自身定位成交通大数据与AI提供商,那么放眼你们的商业环境,又会是另一番景象了。这样既能形成一种商业模式,还能为企业在智能互联网时代打好基础。
中小企业的技术工程师如何破局
现如今对于工程师来说最难的事情就是在自身发展与企业感情间做选择。企业发展好,没感情,干得痛苦;企业发展局限,有感情,又会干得没信心。
本质上,还是如何能接触到更优质的项目?例如:高并发、大数据项目,工程师自己既能得到实战、操练和提升,也能为企业的快速成长提供极有价值的建议,同时自己也不容易被社会发展所淘汰。那么我也给一些分析和办法。
首先并发与大数据的技术问题,终极方案几乎都会转成分布式存储+实时流处理的解决方案,也就是将高并发的请求负载转换成大吞吐、有序队列的方式,降低高并发的同时性请求导致的CPU、内存、I/O这些资源争用的根本性问题,然后通过数据分片,落地在数据库的不同分布式节点中,实现数据upsert的水平伸缩性。
例如:Nginx无论组成有多么高性能的负载群,调度到业务处理、数据库查询和写入都可能会是瓶颈,所以这时候的设计是需要将请求的数据进行队列转换,例如通过Kafka、RocketMQ,然后由流式节点快速的处理掉,而且涉及到流库连接,例如:Hbase、MongoDB、Kudu等实现行级事务就够了。
最后就是如何练习了:需要的业务需求和业务模型直接参考你们企业项目的业务系统,往往业务复杂度和大数据、高并发关系不大。数据集从Google Kaggle下载与你们业务相似的数据集,然后进行清洗改造,这个过程也可以练习一下数据清洗,ETL怎么搞。清洗出自己需要的数据,做成大数据源,Kaggle实在没有与你们业务相类似的数据了,那就自己写模拟客户端程序造数据,跑上3天看结果。
在采集自己的数据源的过程中,尝试kafka,redis,hbase,tidb,mysql,elk,mongodb,hadoop的不同组合的方案效果。最终达到三个目标,1.数据集的ACID事务,2.数据的分布式存储,3.数据的处理和查询实现亚秒级响应。这些搞定的话,其实高并发环境下的大数据事务处理(OLTP)与数据分析(OLAP)架构,最终也跳不出这个架构方案模式。
最关键的是:这个方法适合小数据企业的工程师拿来自己练手,掌握的技术面肯定比大厂工程师更全面,但不否认大厂工程师的实战性认识要深入得多。
最终数据在流式处理后,形成多流聚合,库表业务模型写入,这时候再选择MySQL Cluster或者NewSQL的TiDB,形成关系型数据模型,在分布式事务环境下的数据落地。
查询的过程Nginx+Redis(二级缓存)+MySQL(读写分离负载),或TiDB(分布式数据库)等,配合上MongoDB(部分业务可替换MySQL)和Elasticsearch(搜索引擎),基本上这个模式能扛得住绝大多数的查询响应了。
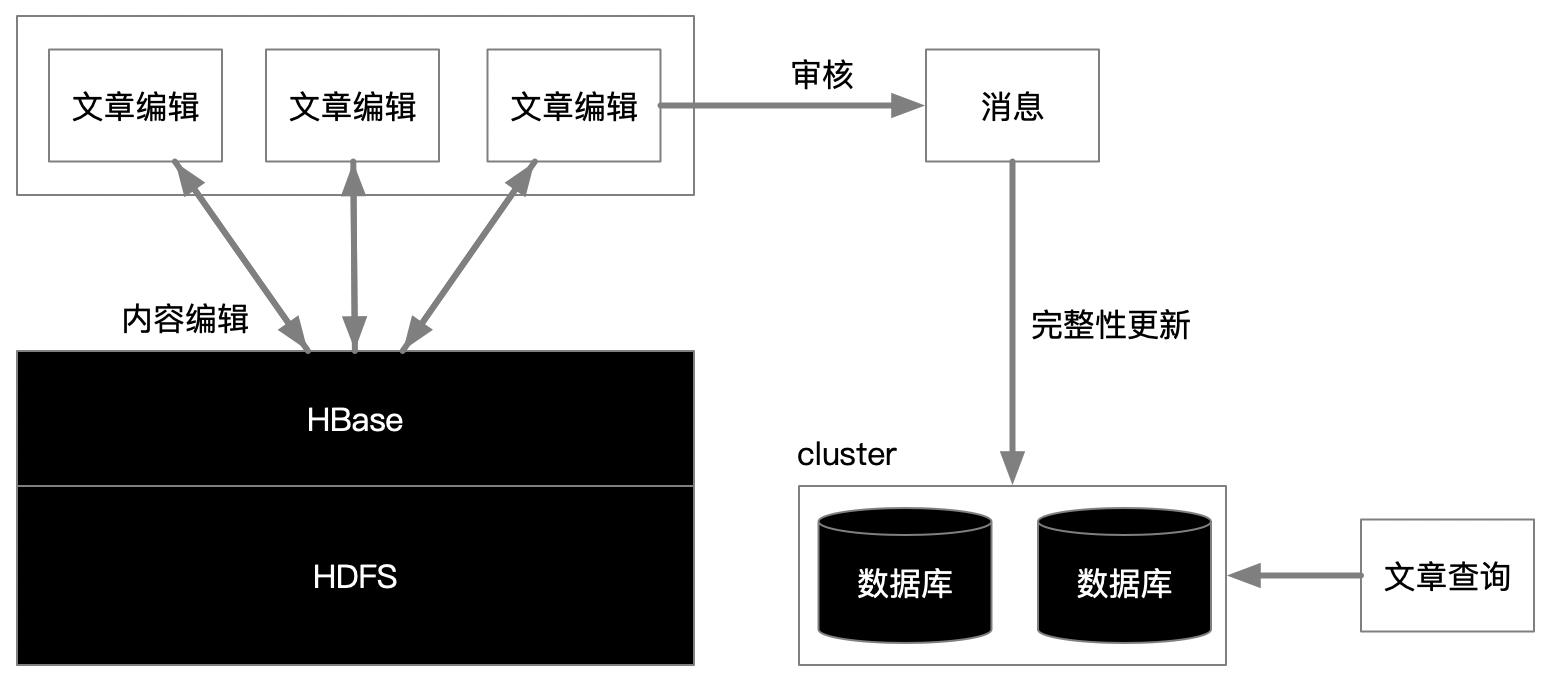
其次我们通过一个实例博客文章架构,如下图所示:看看在极高并发的情况下,每天过亿数据的文章记录产生,是如何架构操作的?
常做自媒体的朋友会知道,文章编辑的过程会频繁地进行修改,云端也会不断保存草稿,作为一个发文章的顶流大站,这种内容频繁写入的规模,是任何关系数据库都是扛不住的,就需要利用大数据平台的K-V数据库特性,实现高速与海量文章的频繁编辑与操作。
然后系统总会在提交后进入一个审核过程,我们总要等待上几秒、几分钟甚至是几十分钟,为什么呢?因为提交的内容正在消息排队,需要等待多久是根据某个时间段内文章发表与修改的队列吞吐量所能处理完的速度决定的,队列处理的过程要进行各种机器AI算法完成对文章内容的流式过滤,例如:敏感词、SH、内容重复等等。
真正意义上的业务关系入库——文章正式发布,是需要等到审核完,这时候才会形成真正地达到了业务一致性,是不是这个时候已经极大的降低了关系数据库的高并发压力。
最后就是如何练习了:需要的业务需求和业务模型直接参考你们企业项目的业务系统,往往业务复杂度和大数据、高并发关系不大。数据集从Google Kaggle下载与你们业务相似的数据集,然后进行清洗改造,这个过程也可以练习一下数据清洗,ETL怎么搞。清洗出自己需要的数据,做成大数据源,Kaggle实在没有与你们业务相类似的数据了,那就自己写模拟客户端程序造数据,跑上3天看结果。
在采集自己的数据源的过程中,尝试kafka,redis,hbase,tidb,mysql,elk,mongodb,hadoop的不同组合的方案效果。最终达到三个目标,1.数据集的ACID事务,2.数据的分布式存储,3.数据的处理和查询实现亚秒级响应。这些搞定的话,其实高并发环境下的大数据事务处理(OLTP)与数据分析(OLAP)架构,最终也跳不出这个架构方案模式。
最关键的是:这个方法适合小数据企业的工程师拿来自己练手,掌握的技术面肯定比大厂工程师更全面,但不否认大厂工程师的实战性认识要深入得多。
可以阅读另一篇关于高并发和大数据技术的详细文章:
博客站的架构渐进升级优化,亿级日写量架构又是什么样呢?
前往读字节创作中心——了解"读字节"更多创作内容

原文转载:http://www.shaoqun.com/a/744773.html
转运四方:https://www.ikjzd.com/w/1342
writer:https://www.ikjzd.com/w/1280
公司的项目数据量有限,获取行业线上线下消费数据也困难,没有足够的数据量,如何应用大数据?如何在公司现有情况下接触实际的高并发大数据项目?就是想实操一下高并发的架构设计或者参与互联网级别项目的开发,但又不想舍弃现在的工作?中小企业如何想办法破局大数据本身就特别容易形成技术垄断,让长尾的中小企业无法形成自己可以拥有的大数据技术方法和经验,导致很难改变小企业的命运,而且也容易导致优质工程师的流失。如何想
kili:https://www.ikjzd.com/w/238
e票联:https://www.ikjzd.com/w/1452
bsci:https://www.ikjzd.com/w/2339
刚度完蜜月 老公就大骂我脸皮厚:http://lady.shaoqun.com/a/271932.html
口述:我新婚夜撒娇竟遭老公掌掴:http://lady.shaoqun.com/m/a/273614.html
Joom平台退款率飙升,主因竟是俄罗斯邮政拒绝平邮?:https://www.ikjzd.com/home/2395
コメントを投稿